Um Ihnen die Funktionen unseres Online-Shops uneingeschränkt anbieten zu können setzen wir Cookies ein. Weitere Informationen

NVIDIA RAPIDS
Nutzen Sie die Leistungsfähigkeit von Grafikprozessoren, um Ihre Workflows für Datenwissenschaft, maschinelles Lernen und KI ganz einfach zu beschleunigen. Führen Sie komplette Workflows für die Datenwissenschaft mit Hochgeschwindigkeits-GPU-Computing und Parallelisieren von Datenladungen, Datenmanipulation und maschinellem Lernen aus – für 50-mal schnellere durchgehende Pipelines für Datenwissenschaft.
Warum RAPIDS?
Datenwissenschaft und maschinelles Lernen (ML) sind das größte Rechensegment weltweit. Bereits geringe Genauigkeitsverbesserungen bei Analysemodellen schlagen sich in Milliardenbeträgen im Endergebnis nieder. Um die besten Modelle zu erstellen, arbeiten Datenwissenschaftler daran, hochpräzise Ergebnisse und leistungsfähige Modelle zu trainieren, zu bewerten, zu iterieren und umzutrainieren. Mit RAPIDS™ dauern Prozesse, die Tage in Anspruch nahmen, nur wenige Minuten, wodurch wertgenerierende Modelle einfacher und schneller erstellt und bereitgestellt werden können. Mit NVIDIA LaunchPad können Sie praxisnahe RAPIDS-Kurse nutzen, und mit NVIDIA AI Enterprise können wir Ihr Unternehmen bei allen Aspekten Ihrer KI-Projekte unterstützen.
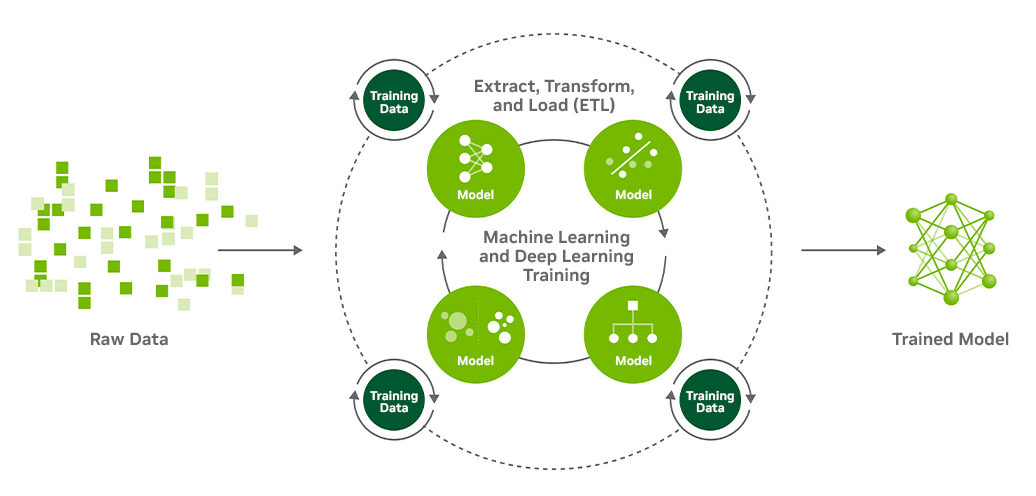
Bei Workflows gibt es viele Iterationen bei der Umwandlung von Rohdaten in Trainingsdaten. Diese werden in viele Algorithmenkombinationen eingespeist, die wiederum einer Hyperparameterabstimmung unterzogen werden, um die passenden Kombinationen von Modellen, Modellparametern und Datenfunktionen für optimale Genauigkeit und Leistung zu finden.
Ein hochleistungsfähiges Ökosystem schaffen
RAPIDS ist eine Suite von quelloffenen Softwarebibliotheken und APIs für die Ausführung von Pipelines für Datenwissenschaft rein auf GPUs – und kann die Trainingszeiten von Tagen auf Minuten verkürzen. RAPIDS basiert auf NVIDIA® CUDA-X AI™ und vereint jahrelange Entwicklung in den Bereichen Grafik, maschinelles Lernen, Deep Learning, High Performance Computing (HPC) und mehr.
 |
Kürzere VerarbeitungszeitenMit Datenwissenschaft können Sie mit mehr Rechenleistung schneller Erkenntnisse gewinnen. RAPIDS nutzt NVIDIA CUDA® im Hintergrund, um Ihre Arbeitsabläufe zu beschleunigen, indem sie die gesamte Pipeline zum Trainieren der Datenwissenschaft auf GPUs ausführen. Dadurch kann die Trainingszeit Ihres Modells von Tagen auf Minuten verkürzt werden. |
 |
Dieselben Tools verwendenIndem die Komplexität der Arbeit mit dem Grafikprozessor und sogar die Kommunikationsprotokolle hinter den Kulissen innerhalb der Rechenzentren verborgen werden, schafft RAPIDS eine einfache Möglichkeit der Datenwissenschaft. Da immer mehr Datenwissenschaftler Python und andere hochrangige Sprachen verwenden, ist die Bereitstellung von Beschleunigung ohne Codewechsel unerlässlich, um die Entwicklungszeit rasch zu verbessern. |
 |
Unternehmenstaugliche DatenwissenschaftDer Zugriff auf zuverlässigen Support ist für Unternehmen, die Datenwissenschaft für geschäftskritische Erkenntnisse nutzen, oft essenziell. Der NVIDIA Enterprise Support ist mit NVIDIA AI Enterprise, einer End-to-End-KI-Softwaresuite, global verfügbar und umfasst garantierte Reaktionszeiten, vorrangige Sicherheitsbenachrichtigungen, regelmäßige Updates und Kontakt zu KI-Experten von NVIDIA. |
 |
Überall skaliert ausführenRAPIDS kann an jedem beliebigen Ort – in der Cloud oder vor Ort – ausgeführt werden. Sie können ganz einfach von einer Workstation auf Server mit mehreren Grafikprozessoren skalieren und es in der Produktion mit Dask, Spark, MLFlow und Kubernetes bereitstellen. |
Ein hochleistungsfähiges Ökosystem schaffen
Die Ergebnisse zeigen, dass Grafikprozessoren bei kleinen und großen Big-Data-Analyseproblemen für große Kosten- und Zeitersparnisse sorgen. Mithilfe vertrauter APIs wie Pandas und Dask kann RAPIDS bei einer Skalierung mit 10 Terabyte bis zu 20-mal schneller auf Grafikprozessoren eingesetzt werden als auf der höchsten CPU-Baseline. Mit nur 16 NVIDIA DGX A100s wird die Leistung von 350 Servern erreicht – damit ist die Lösung von NVIDIA 7-mal kostengünstiger und bietet gleichzeitig eine Leistung auf HPC-Niveau.

Machine Learning to Deep Learning: All on GPU
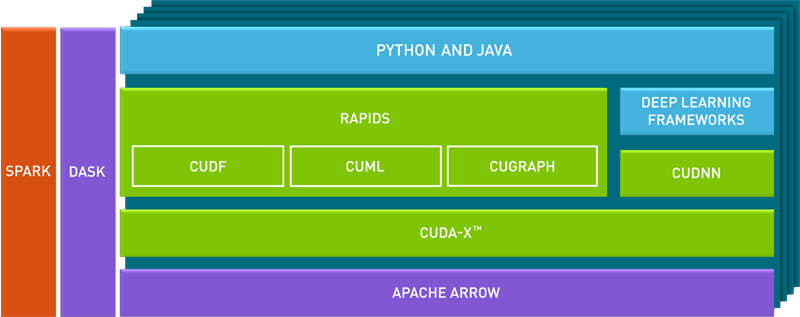
APIDS basiert auf CUDA-Primitives für die Low-Level-Computing-Optimierung, stellt aber diese GPU-Parallelität und hohe Speicherbandbreite durch benutzerfreundliche Python-Schnittstellen zur Verfügung. RAPIDS unterstützt durchgängige Workflows in der Datenwissenschaft, von der Datenladung über die Vorverarbeitung bis hin zum maschinellen Lernen, Grafikanalysen und Visualisierung. Es handelt sich um einen voll funktionsfähigen Python-Stack, der sich für Big-Data-Anwendungsfälle in Unternehmen skalieren lässt.
Machine Learning to Deep Learning: All on GPU
APIDS basiert auf CUDA-Primitives für die Low-Level-Computing-Optimierung, stellt aber diese GPU-Parallelität und hohe Speicherbandbreite durch benutzerfreundliche Python-Schnittstellen zur Verfügung. RAPIDS unterstützt durchgängige Workflows in der Datenwissenschaft, von der Datenladung über die Vorverarbeitung bis hin zum maschinellen Lernen, Grafikanalysen und Visualisierung. Es handelt sich um einen voll funktionsfähigen Python-Stack, der sich für Big-Data-Anwendungsfälle in Unternehmen skalieren lässt.
Haben Sie Fragen zu NVIDIA RAPIDS oder weitere Fragen zu den NVIDIA Produkten?
Wir helfen Ihnen gerne weiter. Rufen Sie uns an, schicken Sie eine Mail.
Kontakt: Tel: +49 40 300672 - 0 | Fax: +49 40 300672 - 11 | E-Mail: info[at]delta.de
