Um Ihnen die Funktionen unseres Online-Shops uneingeschränkt anbieten zu können setzen wir Cookies ein. Weitere Informationen
NVIDIA Grace Hopper
Der NVIDIA Grace™ Hopper™ Superchip ist ein bahnbrechender, beschleunigter Prozessor, der von Grund auf für Anwendungen der künstlichen Intelligenz und des High Performance Computing (HPC) entwickelt wurde. Der Superchip bietet eine bis zu zehnmal höhere Leistung für Anwendungen mit Terabytes an Daten und ermöglicht es Wissenschaftlern und Forschern, völlig neue Lösungen für die komplexesten Probleme der Welt zu finden.

Wenn Sie an einem Test Interesse haben und entsprechende Projekte planen, können wir Sie für einen Test einplanen. Bitte füllen Sie das Anfrageformular für einen kostenlosen Benchmark aus oder schicken Sie uns eine E-Mail. Natürlich nehmen wir auch gerne eine individuelle Softwarekonfiguration vor.
 D14n-M2-GH-EDU
D14n-M2-GH-EDUAb 39.769,21 €
NVIDIA GH200 Grace Hopper Superchip-Server:
- 2HE Rack-Chassis (luftgekühlt)
- redundante 2x 2000W Netzteile
- 4x E1.S" HotSwap für NVMe
- NVIDIA GH200 Grace Hopper Superchip (CG1), 72 Core
- NVIDIA Hopper GPU 144GB HBM3 GPU Memory
- NVIDIA NVLink-C2C 900GB/s internal interconnect
- 480GB LPDDR5X embedded RAM
- bis zu 3x PCI-E 5.0 x16 Slots (FHFL)
 D14n-M2-GH
D14n-M2-GHAb 45.393,59 €
NVIDIA GH200 Grace Hopper Superchip-Server:
- 2HE Rack-Chassis (luftgekühlt)
- redundante 2x 2000W Netzteile
- 4x E1.S" HotSwap für NVMe
- NVIDIA GH200 Grace Hopper Superchip (CG1), 72 Core
- NVIDIA Hopper GPU 144GB HBM3 GPU Memory
- NVIDIA NVLink-C2C 900GB/s internal interconnect
- 480GB LPDDR5X embedded RAM
- bis zu 3x PCI-E 5.0 x16 Slots (FHFL)
 D10n-M2-G
D10n-M2-GAb 20.652,24 €
NVIDIA Grace CPU Superchip-Server
- 2HE Rack-Chassis (luftgekühlt)
- redundante 2x 2000W Netzteile
- 8x E1.S" HotSwap für NVMe
- NVIDIA Grace CPU Superchip, 144 Core
- 480GB LPDDR5X embedded RAM
- 1x 10GBase-T 10GbE Port
- bis zu 7x PCI-E 5.0 x16 Slots (FHFL)
- bis zu 4x GPU/MIC (max. 400 Watt TDP)
Ein genauer Blick auf den Superchip
NVIDIA Grace Hopper Superchip kombiniert die Grace- und Hopper-Architekturen mithilfe von NVIDIA® NVLink®-C2C, um ein kohärentes CPU- und GPU-Speichermodell für beschleunigte KI- und HPC-Anwendungen bereitzustellen.
- CPU+GPU für KI und HPC im großen Maßstab
- Neue kohärente Schnittstelle mit 900 Gigabyte pro Sekunde (GB/s),
7-mal schneller als PCIe der 5. Generation - 30-mal höhere Gesamt-Systemspeicherbandbreite gegenüber GPU im Vergleich zu NVIDIA DGX™ A100
- Führt alle NVIDIA-Software-Stacks und -Plattformen aus, einschließlich des NVIDIA HPC SDK, NVIDIA AI und NVIDIA Omniverse™
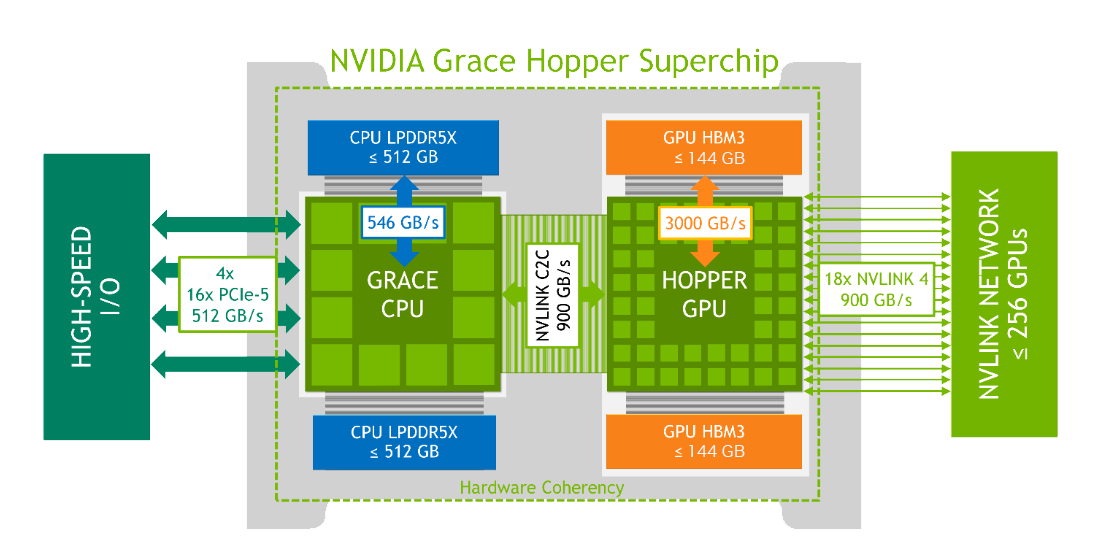
Technische Daten zu NVIDIA Grace Hopper
Die NVIDIA Grace CPU ist die erste Rechenzentrums-CPU von NVIDIA, die von Grund auf für HPC- und KI-Umgebungen entwickelt wurde. Die NVIDIA Grace CPU verwendet 72 Arm Neoverse V2
Cores, um eine führende Pro-Thread-Leistung bei gleichzeitig höherer Energieeffizienz als herkömmliche CPUs zu erreichen. Jede NVIDIA Grace CPU erreicht bis zu 370 Punkte (geschätzt) bei
SPECrate®2017_int_base und garantiert damit hohe Leistung für HPC- und KI-Workloads. Bis zu 512 GB LPDDR5X Speicher bieten eine optimale Balance zwischen Speicherkapazität, Energieeffizienz und Leistung mit bis zu 546 GB/s Speicherbandbreite pro CPU.
| Eigenschaften | Beschreibung |
| Anzahl der Grace CPU | Bis zu 72 ARM Kerne |
| CPU LPDDR5X Bandbreite | Bis zu 500 GB/s |
| GPU HBM3 Bandbreite | 4000 GB/s |
| NVLink C2C Bandbreite | 900 GB/s total, 450 GB/s pro Richtung |
| CPU LPDDR5X Kapazität | Bis zu 512 GB |
| GPU HBM3 Kapazität | Bis zu 96 GB |
| PCIe Gen 5 Lanes | 64x |

NVIDIA NVLink-C2C
NVLink-C2C erweitert die branchenführende NVIDIA® NVLink-Technologie® mit einer Chip-zu-Chip-Verbindung. Dies ermöglicht die Entwicklung einer neuen Klasse von integrierten Produkten mit NVIDIA-Partnern, die über Chiplets entwickelt wurden, sodass NVIDIA-Grafikprozessoren, -DPUs und -CPUs nahtlos mit individueller Hardware verbunden werden können.
| NVIDIA Grace Hopper mit InfiniBand | NVIDIA Grace Hopper mit NVLink |
|
|
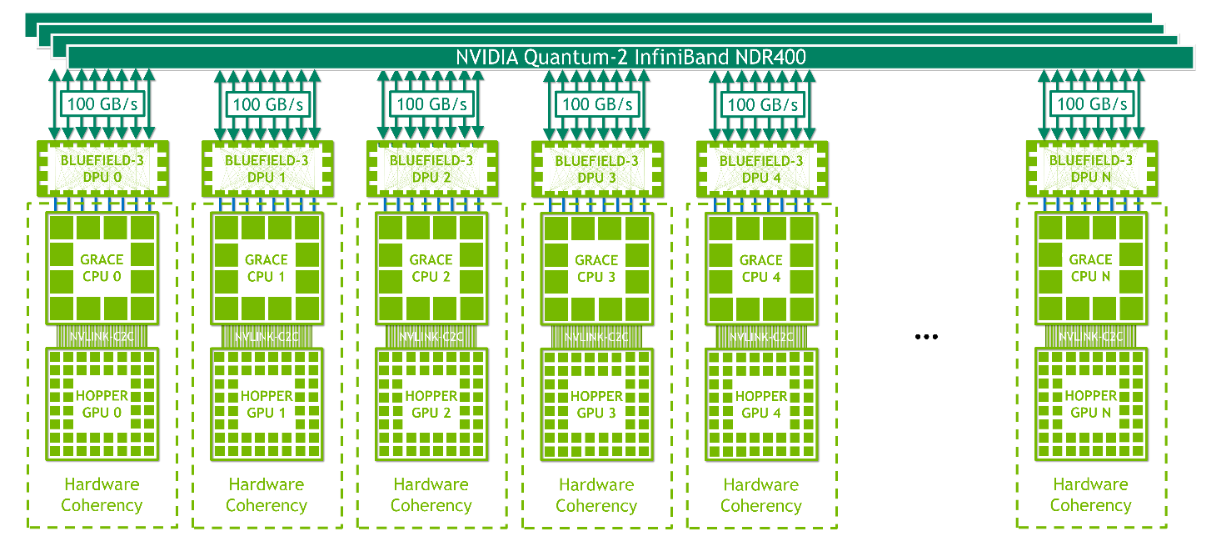
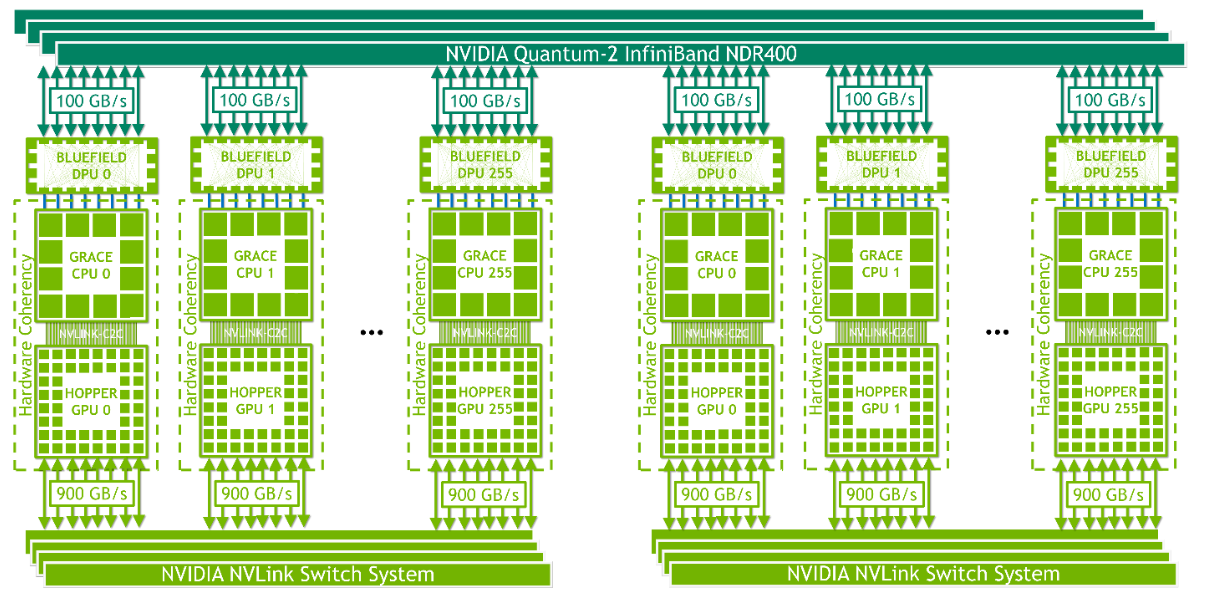
| NVLink-C2C bietet Hardware-Kohärenz innerhalb eines Grace Hopper Superchips. Jeder Knoten enthält einen Grace Hopper Superchip und ein oder mehrere PCIe-Geräte wie NVMe Solid-State-Laufwerke und BlueField-3 DPUs, NVIDIA ConnectX-7 NICs oder OEM-definierte E/A. Diese Nodes sind für Scale-out ML und HPC konzipiert. Mit 16x PCIe Gen 5 Lanes bietet eine NDR400 InfiniBand NIC eine Gesamtbandbreite von bis zu 100 GB/s über die Superchips. Die linke Abbildung zeigt die Vereinfachung der Verwaltung des Clusters. Sie ist konzipiert für Arbeitslasten, die die starken Rechenfähigkeiten von NVIDIA Grace Hopper nutzen können und auch nicht durch den Netzwerkkommunikations-Overhead von InfiniBand behindert werden, das eine der schnellsten verfügbaren Netzwerkverbindungen ist, aber immer noch ein traditionelles RDMA-beschleunigtes Netzwerk. | Der rechte Abbildung mit dem NVLink Switch System ermöglicht jeder Hopper-GPU die Kommunikation mit jeder anderen GPU in der NVLink-Domäne inklusive einer Gesamtbandbreite von 900 GB/s. NVLink TLBs ermöglichen es einer einzelnen GPU, den gesamten über NVLink angeschlossenen Speicher zu adressieren, d. h. bis zu 150 TB Speicher für ein über NVLink angeschlossenes System mit 256 Knoten. Bis zu 256 Superchips können über NVLink in einem Pod verbunden werden, und InfiniBand NICs und Switches verbinden mehrere Superchip-Pods miteinander. NVLink C2C und das NVLink Switch System bieten Hardware-Konsistenz über alle Superchips innerhalb der NVLink-verbundenen Domain. Die hohe Bandbreite und die geringen Latenzzeiten von NVLink in Verbindung mit der Speicherkonsistenz über alle mit NVLink verbundenen Grafikprozessoren und der Möglichkeit, bis zu 150 TB Speicher durch direktes Laden, Speichern und atomare Operationen zu adressieren, machen diese Systemkonfiguration ideal für hochskalierbare maschinelle Lern- und HPC-Workloads und das Training großer KI-Modelle. |
NVIDIA HGX Grace Hopper Superchip vs NVIDIA x86+Hopper
Der NVIDIA HGX Grace Hopper Superchip bietet eine 3,5-fach höhere CPU-Speicherbandbreite pro GPU als x86+Hopper aufgrund des 1:1-Verhältnisses von GPU zu CPU und der hohen LPDDR5X Bandbreite der NVIDIA Grace CPU. NVIDIA Grace Hopper's NVLink C2C bietet eine 7x höhere GPU-CPU-Link-Bandbreite pro GPU gegenüber PCIe Gen 5. Das NVLink Switch System erreicht eine bis zu 9-mal höhere Gesamtbandbreite von GPU zu GPU als InfiniBand NDR400 NICs, die über x16 PCIe Gen5 Lanes verbunden sind. Diese signifikante Verringerung des Rechenaufwands, die Speicherübertragungen zu verbergen, macht das System einfacher zu programmieren und verbessert die Leistung von Anwendungen mit GPU-CPU-Bandbreite.
| Eigenschaften pro GPU | HGX H100 4-GPU (x86) | HGX Grace Hopper | HGX Grace Hopper NVLink Switch |
| CPU Speicher-Bandbreite (pro GPU) | Bis zu 150 GB/s | Bis zu 546 GB/s | Bis zu 546 GB/s |
| GPU Speicher-Bandbreite (pro GPU) | 3000 GB/s | 4000 GB/s | 4000 GB/s |
| CPU Speicher-Bandbreite zu GPU Speicher (pro GPU) | 5% | 12.5% | 12.5% |
| GPU-CPU Link bi-directional Bandbreite (pro GPU) | 128 GB/s (x16 PCIe Gen 5) | 900 GB/s (NVLink C2C) | 900 GB/s (NVLink C2C) |
| GPU-GPU bi-directional Bandbreite (pro GPU) | 100 GB/s (InfiniBand NDR400) | 100 GB/s (InfiniBand NDR400) | 900 GB/s (NVLink 4) |
Haben Sie Fragen zu der NVIDIA Grace Hopper Architektur, helfen oder geben wir Ihnen dazu gerne eine Auskunft.
Kontakt: Tel: +49 40 300672 - 0 | Fax: +49 40 300672 - 11 | E-Mail: info[at]delta.de
