Um Ihnen die Funktionen unseres Online-Shops uneingeschränkt anbieten zu können setzen wir Cookies ein. Weitere Informationen

NVIDIA H100 Tensor Core GPU
Ein Größenordnungssprung für beschleunigtes Computing
Mit der NVIDIA H100 Tensor Core GPU profitieren Sie von beispielloser Leistung, Skalierbarkeit und Sicherheit für jeden Workload. In Verbindung mit dem NVIDIA® NVSwitch™ können bis zu 256 NVIDIA H100 Tensor Core GPUs verbunden werden, um Exascale-Workloads zu beschleunigen, während die dedizierte Transformer Engine Billionen-Parameter-Sprachmodelle unterstützt. Die NVIDIA H100 Tensor Core GPU greift auf Innovationen in der NVIDIA Hopper™-Architektur zurück, um eine branchenführende Sprach-KI anzubieten und große Sprachmodelle bis zum 30-fachen im Vergleich zur Vorgeneration zu beschleunigen.
Echtzeit-Deep-Learning-Inferenz
KI löst eine Vielzahl von geschäftlichen Herausforderungen mit einer ebenso breiten Palette an neuronalen Netzen. Ein hervorragender KI-Inferenzbeschleuniger muss nicht nur höchste Leistung, sondern auch die Vielseitigkeit bieten, um diese Netzwerke zu beschleunigen.
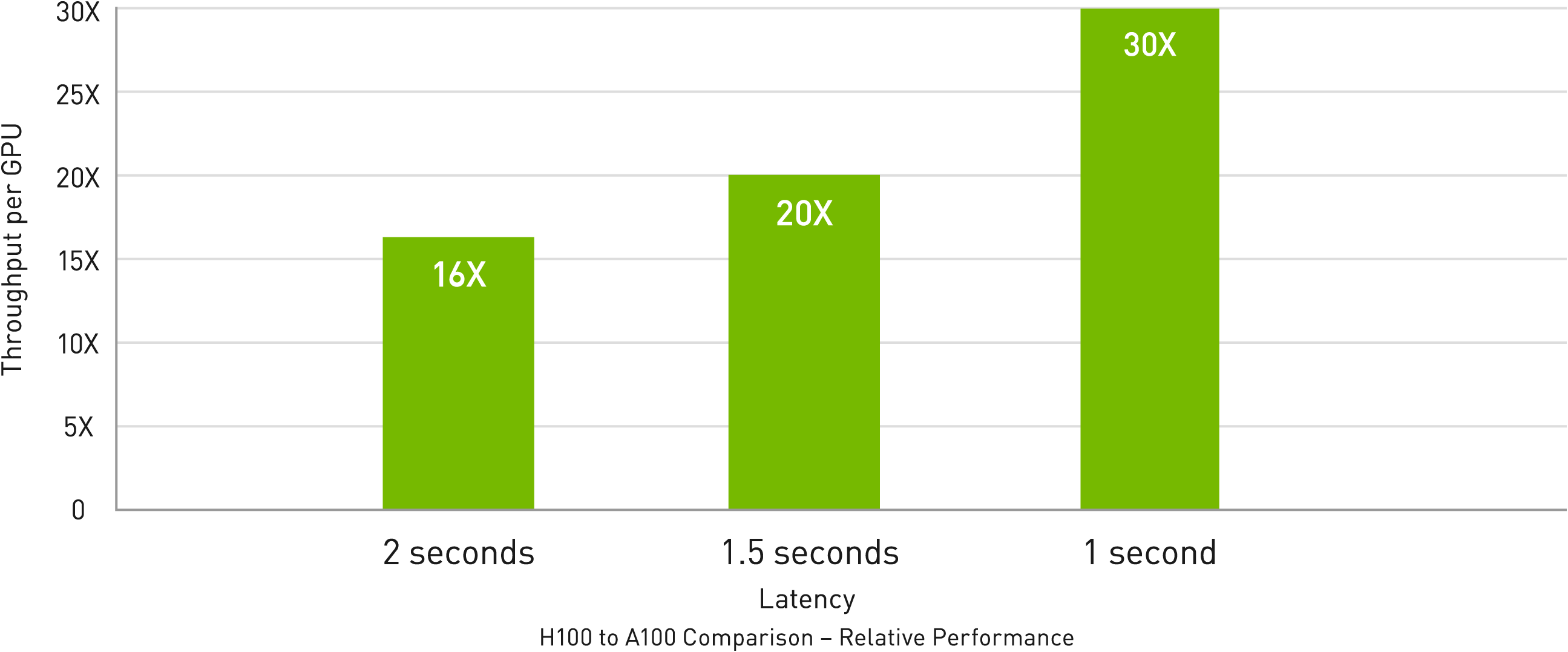
NVIDIA H100 Tensor Core GPU erweitert die marktführende Position von NVIDIA bei Inferenz weiter mit mehreren Fortschritten, die die Inferenz um das bis zu 30-Fache beschleunigen und die niedrigste Latenz bieten. Tensor-Recheneinheiten der vierten Generation beschleunigen alle Präzisionen, einschließlich FP64, TF32, FP32, FP16 sowie INT8, und die Transformer Engine verwendet FP8 und FP16 zusammen, um die Speicherauslastung zu reduzieren, die Leistung zu steigern und gleichzeitig die Genauigkeit für große Sprachmodelle aufrechtzuerhalten.
Mit der NVIDIA H100 Tensor Core GPU profitieren Sie von beispielloser Leistung, Skalierbarkeit und Sicherheit für jeden Workload.
■ 640GB GPU Memory (HBM3)
■ 18x NVIDIA® NVLink® (4. Generation) pro GPU
■ 900 GB/s bidirektionale Bandbreite
■ Bis zu 256x GPUs per NVIDIA® NVSwitch™ in einem NVIDIA DGX SuperPOD™-Verbund

Exascale High-Performance Computing
Die NVIDIA-Rechenzentrumsplattform bietet konsistent Leistungssteigerungen, die über das Mooresche Gesetz hinausgehen. Die neuen bahnbrechenden KI-Funktionen der NVIDIA H100 Tensor Core GPU verstärken die Leistungsfähigkeit von HPC + KI weiter, um für Wissenschaftler und Forscher, die an der Lösung der wichtigsten Herausforderungen der Welt arbeiten, die Zeit bis zum Entdecken zu verkürzen.
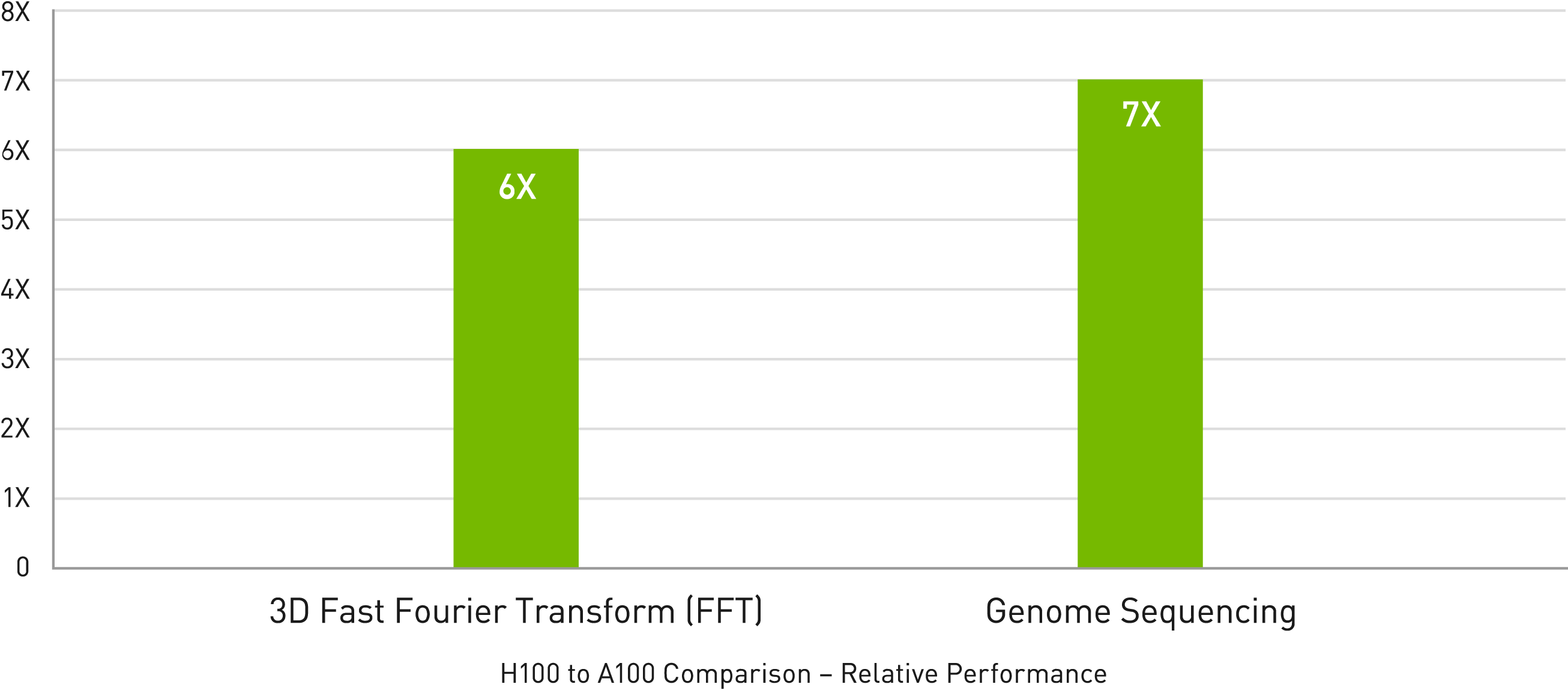
NVIDIA H100 Tensor Core GPU verdreifacht die Gleitkommaoperationen pro Sekunde (FLOPS) der Tensor Cores mit doppelter Genauigkeit und liefert 60 TeraFLOPS FP64-Computing für HPC. KI-gestützte HPC-Anwendungen können die TF32-Präzision der NVIDIA H100 Tensor Core GPU nutzen, um einen PetaFLOPS Durchsatz für Matrixmultiplikationsoperationen mit einfacher Genauigkeit zu erreichen, ohne Codeänderungen.
Die NVIDIA H100 Tensor Core GPU verfügt außerdem über DPX-Anweisungen, die bei dynamischen Programmieralgorithmen wie Smith-Waterman für die DNA-Sequenzausrichtung 7-mal mehr Leistung als NVIDIA A100 Tensor Core GPUs und eine 40-fache Beschleunigung gegenüber herkömmlichen Servern mit Dual-Socket-CPUs allein bieten.
Aktivieren Sie Ihre NVIDIA AI Enterprise Lizenz für die H100
NVIDIA H100 Tensor Core GPU enthält ein kostenloses 5 Jahres-Abonnement für Software, Support und Schulungen.
Kunden müssen ihren NVIDIA H100-Grafikprozessor registrieren, um Zugriff auf ihr NVIDIA AI Enterprise-Abonnement zu erhalten.

MIG der zweiten Generation
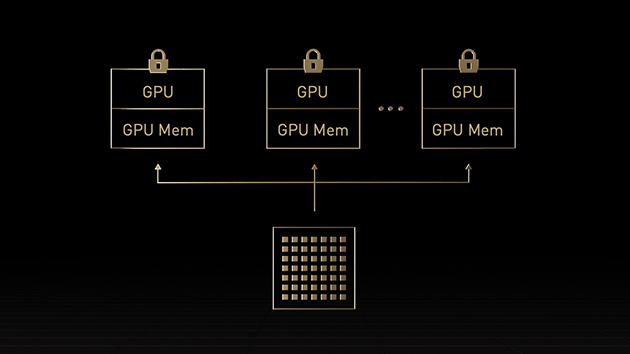
Ein Mehr-Instanzen-Grafikprozessor (MIG) kann in mehrere kleinere, vollständig isolierte Instanzen mit eigenem Speicher, Cache und Recheneinheiten aufgeteilt werden. Die NVIDIA Hopper™ Architektur verbessert MIG noch weiter und unterstützt mandantenfähige Multi-User-Konfigurationen in virtualisierten Umgebungen für bis zu sieben Grafikprozessorinstanzen, wobei jede Instanz durch Confidential Computing sicher auf Hardware- und Hypervisorebene isoliert ist. Dedizierte Videodecoder für jede MIG-Instanz erlauben intelligente Videoanalysen (IVA) mit hohem Durchsatz auf gemeinsam genutzter Infrastruktur. Mit dem gleichzeitigen MIG-Profiling von Hopper können Administratoren die korrekt dimensionierte Grafikprozessorbeschleunigung überwachen und die Ressourcenzuweisung für Benutzer optimieren.
Forscher mit kleineren Workloads können anstelle einer vollständigen CSP-Instanz MIG verwenden, um einen Teil eines Grafikprozessors sicher zu isolieren, und sich dabei darauf verlassen, dass ihre Daten bei Lagerung, Übertragung und Verarbeitung geschützt sind.
Der Formfaktor der H100 im Vergleich
NVIDIA H100 Tensor Core GPU (SXM) | NVIDIA H100 Tensor Core GPU (PCIe) | NVIDIA H100 NVL Tensor Core GPU (PCIe) | |
| FP64 | 34 teraFLOPS | 26 teraFLOPS | 68 teraFLOPS |
| FP64-Tensor-Core | 67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPS |
| FP32 | 67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPS |
| TF32-Tensor-Core | 989 teraFLOPS | 756 teraFLOPS | 1979 teraFLOPS |
| BFLOAT16-Tensor-Core | 1979 teraFLOPS | 1513 teraFLOPS | 3958 teraFLOPS |
| FP16-Tensor-Core | 1979 teraFLOPS | 1513 teraFLOPS | 3958 teraFLOPS |
| FP8-Tensore-Core | 3958 teraFLOPS | 3026 teraFLOPS | 7916 teraFLOPS |
| INT8-Tensor-Core | 3958 TOPS | 3026 TOPS | 7916 TOPS |
| GPU-Speicher | 80 GB | 188 GB | |
| GPU-Speicherbandbreite | 3.35 TB/s | 2 TB/s | 7.8 TB/s |
| Decoder | 7 NVDEC 7 JPEG | 14 NVDEC 14 JPEG | |
| Max. Thermal Design Power (TDP) | 700 W (konfigurierbar) | 300 - 350 W (konfigurierbar) | 2x 350-400 W (konfigurierbar) |
| Multi-Instance-GPUs | Bis zu 7 MIGs mit je 10 GB | Bis zu 14 MIGS mit je 12 GB | |
| Formfaktor | SXM | PCIe (luftgekühlt) | 2x PCIe (luftgekühlt) |
| Konnektivität | NVIDIA® NVLink® vierte Generation : 900 GB/s PCIe Gen5: 128 GB/s (18x NVLink Links mit 25 GB/s pro Richtung) | NVIDIA® NVLink® dritte Generation : 600 GB/s PCIe Gen5: 128 GB/s | NVIDIA® NVLink® dritte Generation : 600 GB/s PCIe Gen5: 128 GB/s |
| Serveroptionen | NVIDIA HGX™ H100-Partner und NVIDIA-Certified Systems™ mit 4 oder 8 GPUs, NVIDIA DGX™ H100 mit 8 GPUs | Partner und NVIDIA-Certified Systems mit 1–8 GPUs | Partner und NVIDIA-Certified Systems mit 2–4 GPUs |
| NVIDIA AI Enterprise | Add-on | Included | Add-on |
| weitere Informationen | Datasheet | ||
Preisübersicht der einzelnen GPU
Passende Systeme zu der NVIDIA H100 Tensor Core GPU
Die NVIDIA Hopper™ Architektur im Detail
Der technische Blog von NVIDIA ist gefüllt mit einer Menge an Informationen, originalen Bildern, Skizzen sowie Tabellen.
Die komplette Architektur wird im Detail behandelt und genaustens beschrieben.
Haben Sie Fragen zu der NVIDIA H100 Tensor Core GPU oder weitere Fragen zu den NVIDIA Produkten?
Wir helfen Ihnen gerne weiter. Rufen Sie uns an, schicken Sie eine Mail oder nutzen Sie uner Anfrageformular: NVIDIA DGX™ Angebot
Kontakt: Tel: +49 40 300672 - 0 | Fax: +49 40 300672 - 11 | E-Mail: info[at]delta.de
