Um Ihnen die Funktionen unseres Online-Shops uneingeschränkt anbieten zu können setzen wir Cookies ein. Weitere Informationen
NVIDIA DGX GB200 NVL72
Der DGX GB200 NVL72 verbindet 36 Grace-CPUs und 72 Blackwell-GPUs in einem Rack. Die Rack-Lösung wird ausschließlich mit Flüssigkeit gekühlt. In einer NVLink-Domäne mit 72 Grafikprozessoren, die als einzelner riesiger Grafikprozessor funktioniert und 30-mal schnellere Echtzeit-Inferenz für LLMs mit Billionen Parametern bietet.
Der GB200 Grace Blackwell Superchip ist eine Schlüsselkomponente des NVIDIA GB200 NVL72 und verbindet zwei hochleistungsfähige NVIDIA Blackwell GPUs und eine NVIDIA Grace-CPU über die NVIDIA® NVLink®-C2C-Verbindung mit den beiden Blackwell-GPUs.
GB200 NVL72 Technische Daten
Funktion
- Konfiguration
- FP4 Tensor-Recheneinheit
- FP8/FP6 Tensor-Recheneinheit
- INT8-Tensor-Recheneinheit
- FP16/BF16 Tensor-Recheneinheit
- FP16/BF16 Tensor-Recheneinheit
- FP64 Tensor-Recheneinheit
- Grafikprozessorspeicher | Bandbreite
- NVLink-Bandbreite
- Anzahl der CPU-Recheneinheiten
- CPU-Speicher | Bandbreite
GB200 Grace Blackwell Superchip
- 1 Grace-CPU: 2 Blackwell
- 40 PFLOPS
- 20 PFLOPS
- 20 POPS
- 10 PFLOPS
- 5 PFLOPS
- 90 TFLOPS
- Bis zu 384 GB HBM3e | 16 TB/s
- 3,6 TB/s
- 72 Arm® Neoverse V2-Recheneinheiten
- Bis zu 480 LPDDR5X | Bis zu 512 GB/s
GB200 NVL72
- 36 Grace-CPU: 72 Blackwell
- 1.440 PFLOPS
- 720 PFLOPS
- 720 POPS
- 360 PFLOPS
- 180 PFLOPS
- 3.240 TFLOPS
- Bis zu 13,5 TB HBM3e | 576 TB/s
- 130 TB/s
- 2.592 Arm® Neoverse V2-Recheneinheiten
- Bis zu 17 TB LPDDR5X | Bis zu 18,4 TB/s
Vom Superchip zum SuperPOD

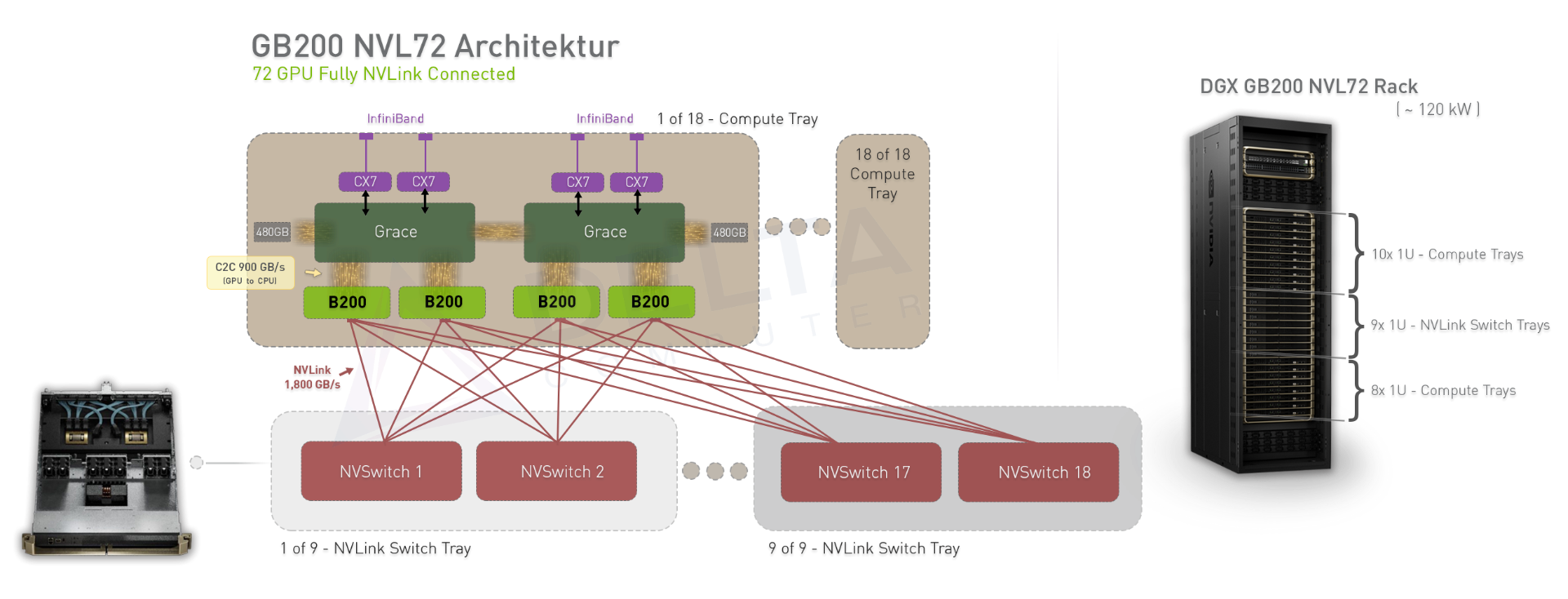
In obiger Skizze haben wir die GB200 NVL72 Architektur dargestellt. Die Architektur skaliert mit 8x GB200 NVL Systemen auf 576x B200 GPUs in einer NVLink Domäne.
Wenn Sie Fragen dazu haben, kontaktieren Sie uns einfach per Mail oder über das Anfrageformular
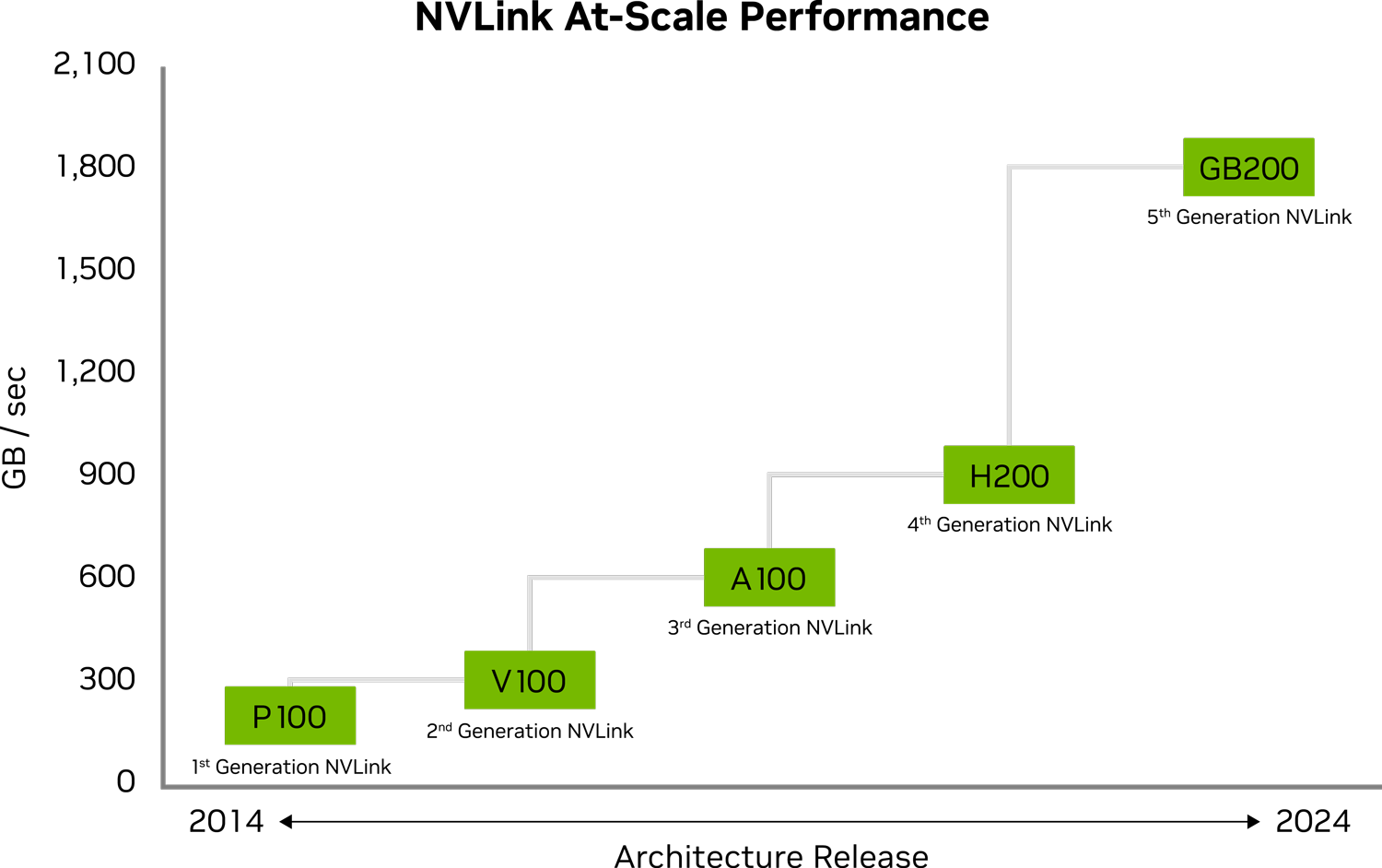
NVLink Spezifikationen
Second Gen | Third Gen | Fourth Gen | Fifth Gen | |
| NVLink bandwidth per GPU | 300 GB/s | 600 GB/s | 900 GB/s | 1800 GB/s |
| Number of Links / GPU | 6 | 12 | 18 | 18 |
| Total aggregate bandwidth | 2.4 TB/s | 4.8 TB/s | 7.2 TB/s | 1 PB/s |
| Number of GPUs connected | Up to 8 | Up to 8 | Up to 8 | Up to 576 |
NVLink der fünften Generation verbessert die Skalierbarkeit für größere Multi-GPU-Systeme erheblich. Ein einzelner NVIDIA Blackwell Tensor Core Grafikprozessor unterstützt bis zu 18 NVLink Verbindungen mit 100 Gigabyte pro Sekunde (GB/s) für eine Gesamtbandbreite von 1,8 Terabyte pro Sekunde (TB/s) - 2 x mehr Bandbreite als bei der vorherigen Generation und über 14 x mehr Bandbreite als bei PCIe Gen5. Serverplattformen wie der GB200 NVL72 nutzen diese Technologie, um eine größere Skalierbarkeit für die komplexesten Großmodelle von heute zu bieten.
Haben Sie Fragen zu der NVIDIA GB200 NVL72 Lösung, helfen oder geben wir Ihnen dazu gerne eine Auskunft. Gerne können Sie auch den Live Chat Button rechts unten auf der Webseite nutzen.
Kontakt: Tel: +49 40 300672 - 0 | Fax: +49 40 300672 - 11 | E-Mail: info[at]delta.de
